



About team VLM
● Mission:
Advance multimodal learning in Medical AI by creating VLMs that seamlessly fuse medical imaging, physiological signals, clinical text, and structured knowledge.
● Scope:
Tackle real-world clinical tasks such as diagnosis, prognosis, explanation, question answering, and more.
● Goal:
Deliver robust, clinically deployable AI that supports healthcare professionals and ultimately improves patient care.
Available internship topics
● Self-correcting-based Image-Text Alignment for Radiology Report Generation
● Mitigating Hallucinations in Medical VLMs for Medical VQA.
Our research topics
Optimizing medical VLMs via clinical-aware preference alignment
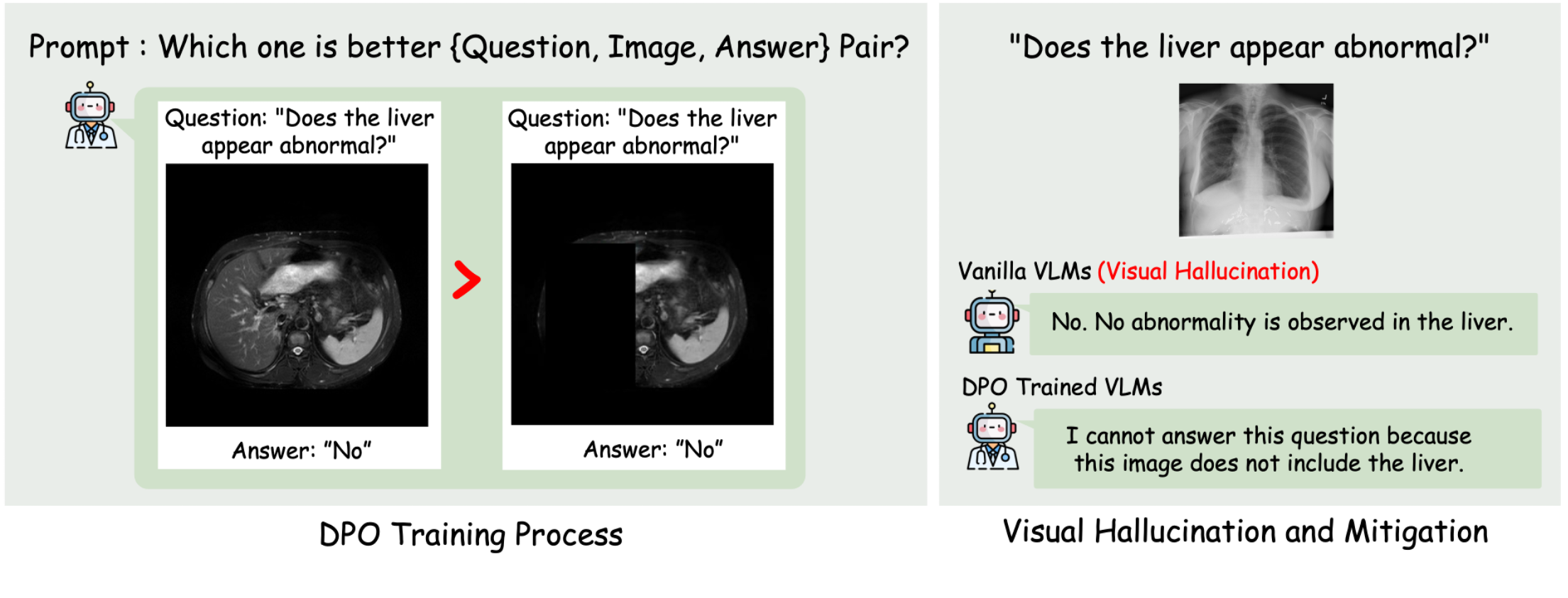
● We improve trustworthiness in medical VLMs by mitigating diverse hallucination types in complex medical reasoning tasks through clinical-aware image-text alignment.
● We develop optimization methods based on Direct Preference Optimization (DPO), RLH/AIF to align model outputs with clinical image-text evidence.
Related publications
[CVPR'25] DART: Disease-aware Image-Text Alignment and Self-correcting Re-alignment for Trustworthy Radiology Report Generation
Developing clinical knowledge-guided refinement frameworks with retrieval-augmented generation (RAG)
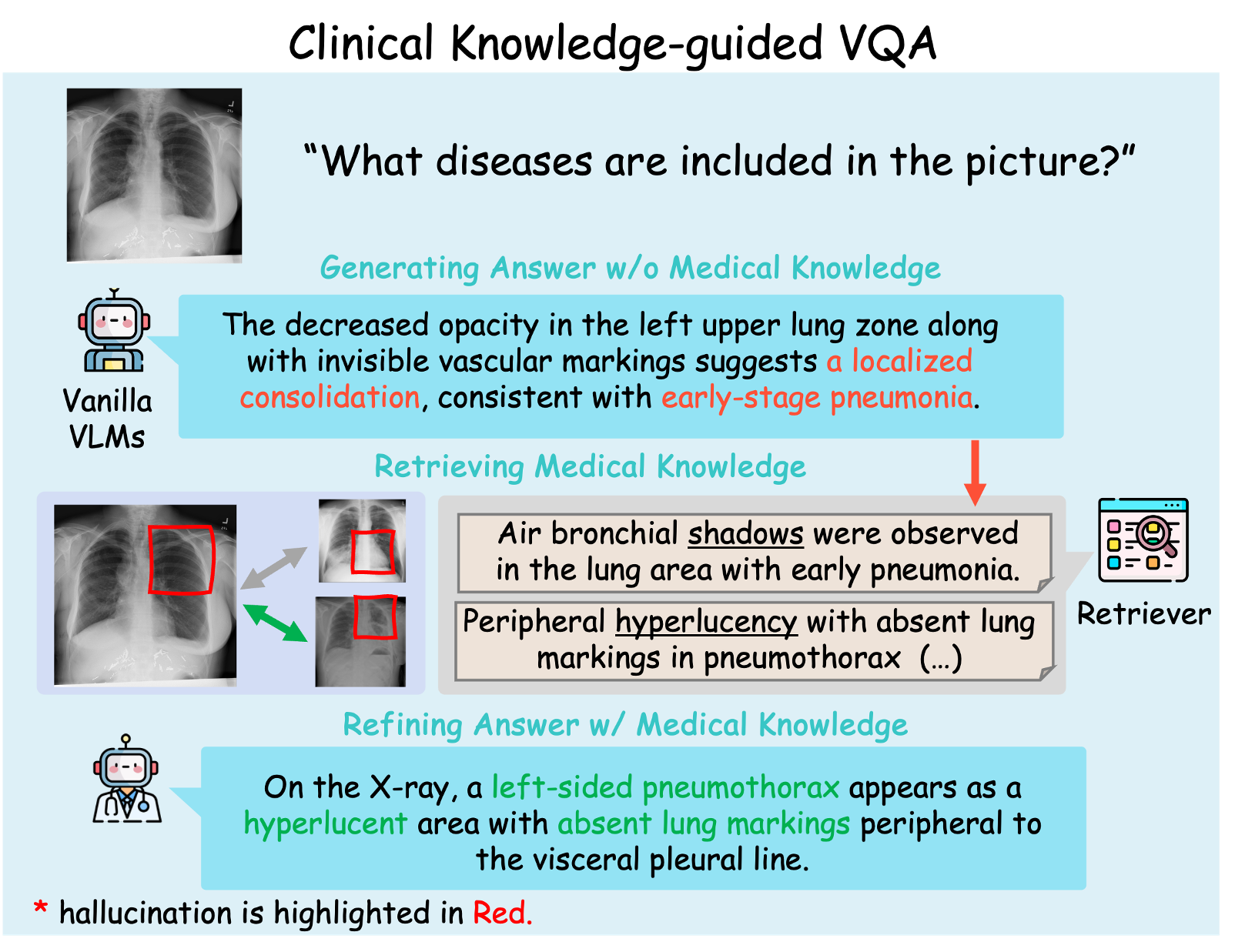
● We seek to enhance the factual consistency and clinical validity of medical VLM outputs by grounding them in case-based and knowledge-based evidence.
● We develop a retrieval-augmented generation framework that fuses retrieved images and clinical texts using a knowledge-guided refinement module.
Generating pathology-aligned radiology reports
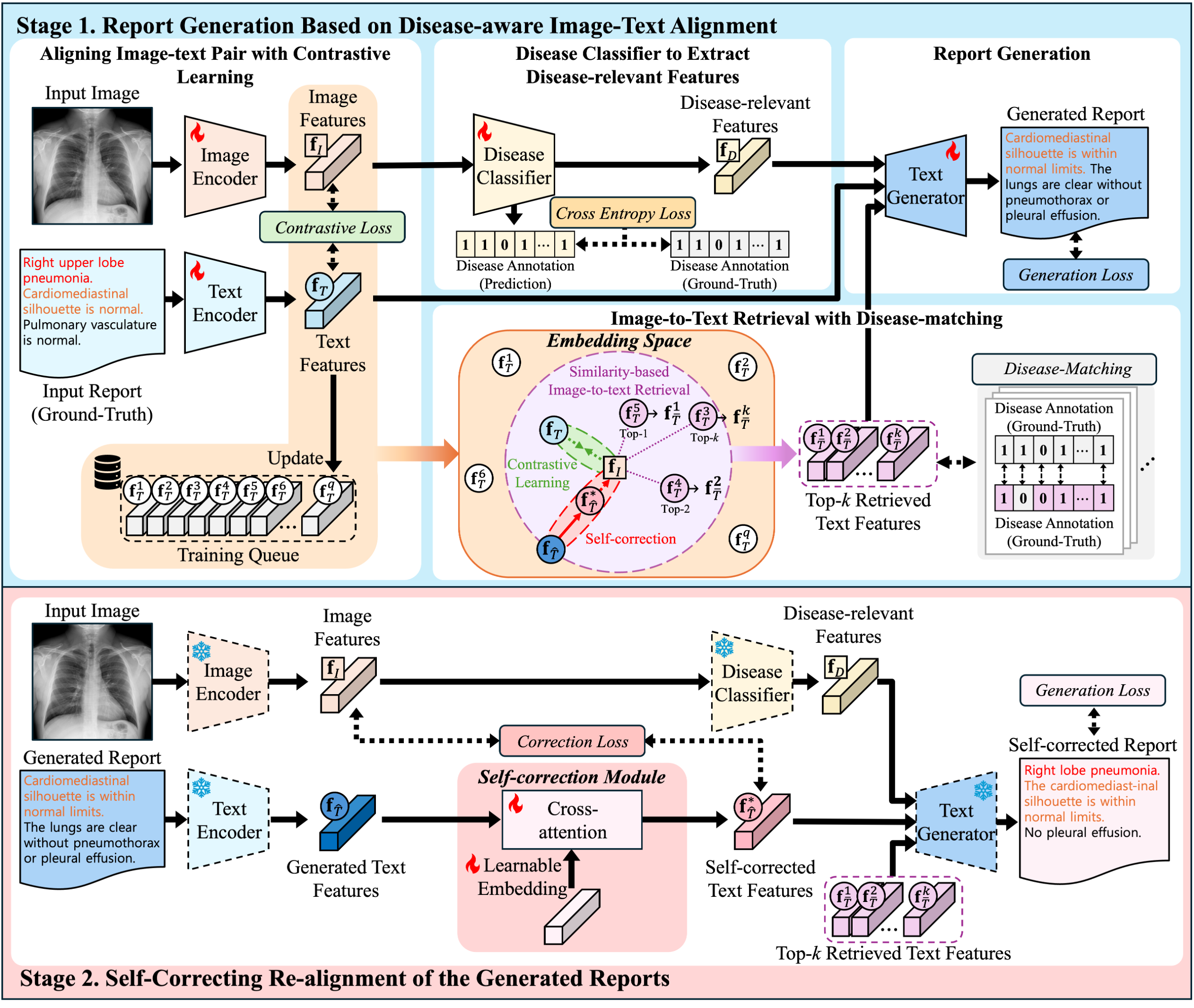
● We aim to generate radiology reports that are visually grounded and free from omissions or hallucinations.
● We design a self-correction pipeline that retrieves pathology-matched reports and iteratively aligns each sentence with the source image to refine the output.
Related publications
[CVPR'25] DART: Disease-aware Image-Text Alignment and Self-correcting Re-alignment for Trustworthy Radiology Report Generation
Designing interpretable reasoning frameworks for medical VLMs
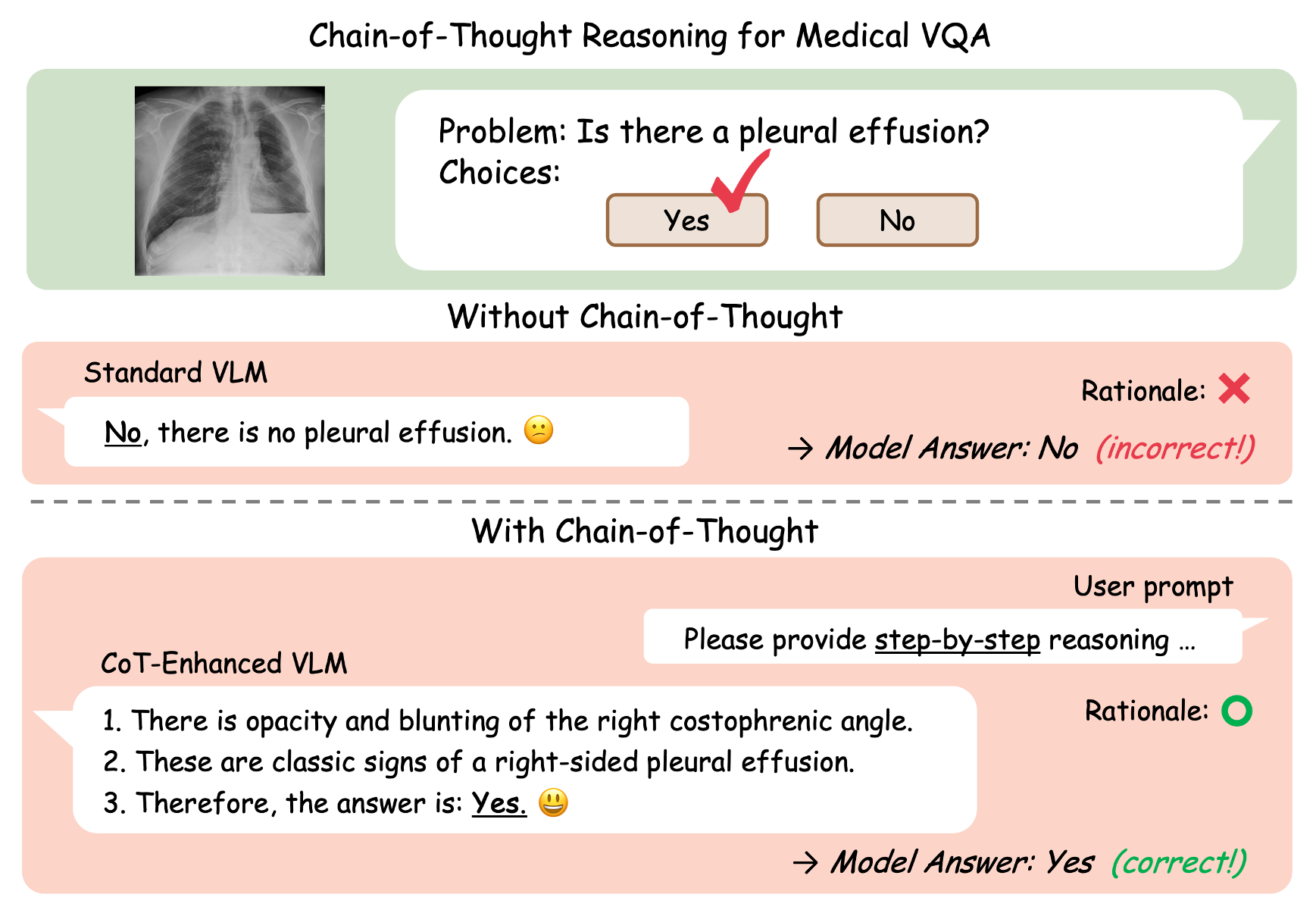
● We aim to equip VLMs with expert-level reasoning capabilities for complex diagnostic tasks involving multiple images or modalities.
● We develop interpretable modules based on chain-of-thought prompting, cross-image evidence aggregation, and self-verifying rationales to support transparent and auditable inference.